
The Stack Beneath the Interface
Why subsidized AI access does not yet build AI capability

The Subsidy Paradox
In 2026, India’s Ministry of Electronics and Information Technology reported that the IndiaAI Mission’s common compute facility had onboarded 38,231 graphics processing units through 14 empaneled service providers and data centers. The facility was meant to provide startups, researchers, academia, and other eligible users with access to AI compute through domestic cloud providers.
The pricing was striking. According to a parliamentary reply, the facility was offering compute at an average subsidized rate of Rs 65 per GPU hour, except for select high-end GPUs.
The objective was direct: give Indian startups, researchers, and public institutions cheaper access to the computational infrastructure now required to build and deploy advanced AI systems. For a country pursuing AI capability at scale, the logic is clear. Compute has become foundational infrastructure, and infrastructure access changes who can build.
The compute subsidy widens access, but the GPUs it rents still sit inside supply chains India does not control. Advanced AI chips depend on design, fabrication, and semiconductor supply networks concentrated outside India, and they are often reached through cloud infrastructure shaped by firms outside India. The Indian state is widening domestic access to AI, but much of the technological frontier it is subsidizing remains controlled elsewhere.
The access-with-dependence pattern is not uniquely Indian. India makes it unusually visible. Many technology middle powers are entering AI through adoption, cloud access, model adaptation, and subsidized compute rather than full-stack control. They can accelerate domestic use while remaining dependent at depths that become more strategically important over time.
The compute subsidy carries a double effect: it can widen domestic access and deepen strategic dependence at once. The user-facing interface of cheaper GPU hours, APIs, models, and applications becomes easier to reach. The substrate underneath, from chips and cloud systems to data centers and energy, remains expensive, concentrated, and outside Indian governance.
Subsidized compute therefore does more than lower prices for domestic users. It also channels public support through domestic providers into a global hardware and cloud ecosystem whose most valuable components remain in external hands.
The subsidy is making access easier. The more important question remains: what kind of capability is India building when the user-facing layer becomes cheaper while the underlying infrastructure remains concentrated elsewhere?
The answer lies in the stack beneath the interface.
The Infrastructure Behind the Interface
Seen from the surface, the public experience of subsidized AI is deceptively lightweight. A user opens a browser, enters a prompt, and receives a fluent answer. A developer calls an API or adapts an open-weight model for a narrower task. A hospital integrates an AI assistant into transcription workflows. A state government tests translation tools across regional languages. From the user’s perspective, intelligence appears as software: accessible through interfaces, downloadable in compressed weights, deployable at low marginal cost.
That surface experience is real. The barriers to experimentation have fallen, sometimes dramatically. Open-source tools have proliferated. Smaller teams can now build products that would have required much larger research organizations a decade ago. For many practical tasks, no one needs to train a large model from scratch anymore.
But openness at the interface is not openness across the stack.
Underneath the interface is a layered system. Applications depend on models and inference services; those depend on cloud capacity, chips, fabrication networks, data centers, energy, and the software systems that connect them. The layers connect, but they do not share the same economics or the same concentration of power.
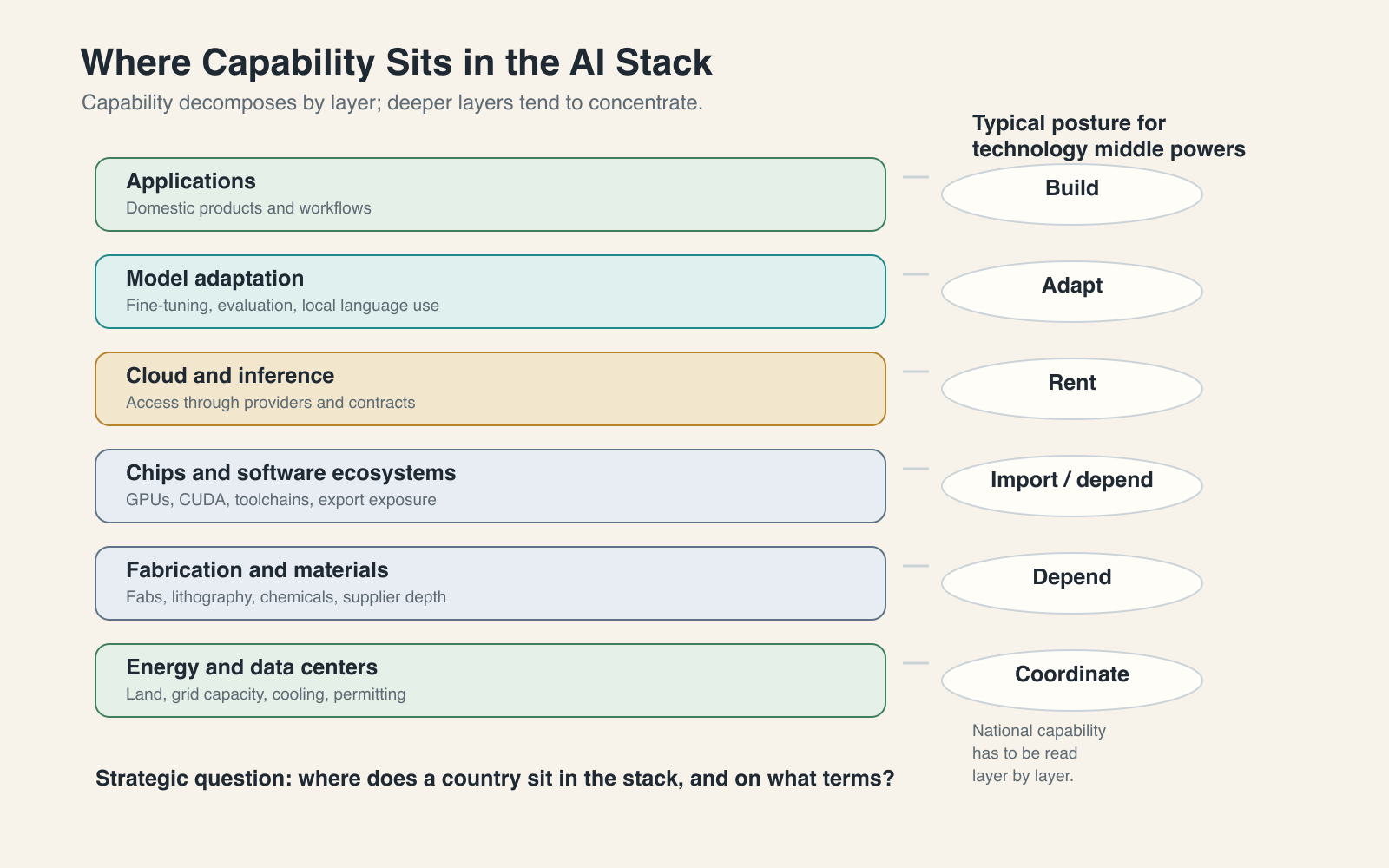
AI’s cost structure runs on two questions: what becomes cheaper, and what remains scarce. At the application layer, inference is cheap and getting cheaper. At the compute layer, frontier training is expensive and tightly held. As one moves down the stack, capital intensity rises, and with it concentration, because fewer actors can fund the depth. Surface accessibility is consistent with stack-wide concentration.
Consider the chip layer. Modern AI depends on advanced GPUs and related accelerators whose design requires accumulated architectural expertise and mature software ecosystems. Fabricating these chips requires extreme-ultraviolet lithography systems, advanced manufacturing capacity concentrated in firms such as TSMC and Samsung, and supply chains spanning highly specialized chemical, equipment, and materials ecosystems. The chokepoints are not accidental. They are the outcome of decades of globalization optimizing for efficiency through specialization. AI changed the strategic significance of that specialization; it has not loosened the chokepoints.
The software layer compounds the concentration. NVIDIA’s position in AI does not come only from hardware performance. It comes from CUDA: a deeply embedded software ecosystem around which machine learning tools, optimization libraries, developer workflows, and research pipelines have accumulated for over a decade. These ecosystems also shape training pathways. When engineers learn frontier AI through the libraries, deployment practices, and optimization routines of a dominant toolchain, talent formation reinforces the technical stack it depends on. A rival chip is not just competing against silicon. It is competing against an ecosystem.
Cloud infrastructure adds another dependency. Most startups, universities, and public agencies do not build large AI compute clusters themselves; they rent capacity. This lowers upfront costs and speeds adoption, but it also means that domestic AI capability is mediated by a small number of global cloud providers whose pricing, availability, infrastructure footprints, and geopolitical exposure shape what downstream actors can build.
Inference costs deepen the dependency further. Public attention often focuses on training; for most firms and states, the longer-term challenge is serving AI systems reliably and cheaply at scale. Every inference request consumes compute, electricity, cooling capacity, and network infrastructure. Recurring inference costs may become more strategically significant than one-time training expenditures.
And then there is energy.
Data centers are physical systems. They require land, electricity, cooling, water, and the planning needed to bring them together. India’s Ministry of Electronics and Information Technology has said that the country’s data-center capacity increased from about 375 MW in 2020 to around 1,500 MW by 2025. Industry estimates suggest it could exceed 4,500 MW in the next five to six years.
At that scale, AI is not only a software system. It is a claim on electricity, land, cooling, transmission infrastructure, and administrative coordination. The bottleneck for data-center expansion is rarely the model itself. It is grid capacity, site selection, power procurement, water management, and the state’s ability to assemble large infrastructure projects in compressed timeframes.
Localization does not eliminate dependence. A startup hosting a model on domestic infrastructure may still depend on foreign chips, external model architectures, third-party benchmarks, and global developer ecosystems. A drone running on-board inference may still rely on a retraining pipeline whose updates it cannot survive without. The moves intended to reduce dependence can leave hidden dependencies intact.
The stack decomposes by layer and concentrates by depth. It also changes the kind of binding constraint at each layer. At the chip layer, the constraint is industrial and geopolitical: fabrication knowledge, equipment chokepoints, supplier ecosystems, and export exposure. At the data-center layer, the constraint shifts toward administration: land, grid capacity, power procurement, and the state’s ability to assemble infrastructure quickly. Strategy has to differ by layer because the constraint differs by layer.
India’s Layered Capability
India enters the AI transition with real strengths.
India has a large software-services ecosystem, a deep pool of engineering talent, a large domestic market, and experience deploying digital systems across scale and heterogeneity. These capabilities matter. They will matter increasingly as AI moves into adaptation, deployment, and operational integration rather than only frontier model development.
But India’s strengths sit unevenly across the stack.
At the application layer, India is relatively well-positioned. Startups, enterprises, and public institutions can build on top of existing models and create tools for sectors such as healthcare, education, financial services, and agriculture. The application layer is competitive globally, and India is in that competition.
At the middle of the stack, the picture is mixed. India has growing capability in model adaptation, AI operations, software integration, and workflow automation, among others. But many of these capabilities still depend on external model architectures, foreign cloud infrastructure, imported chips, and global developer ecosystems. India has real middle-layer capability, but not middle-layer independence.
Dependence runs deepest at the base of the stack. Frontier compute, advanced semiconductor fabrication, hyperscale cloud capacity, and the dominant AI software ecosystems remain concentrated outside India. The IndiaAI subsidy reaches into these depths as a buyer, not as a producer.
Layered structure matters because the Indian AI debate often treats capability as flat. The success of Aadhaar, UPI, and related digital public infrastructure created a powerful narrative: India could compensate for late industrialization in some domains through scale, public digital rails, and institutional coordination.
Digital public infrastructure is the name now commonly used for shared, secure, and interoperable digital systems that support access to public and private services. In India, Aadhaar, UPI, DigiLocker, and related data-exchange systems made that idea globally visible. They showed that state-backed digital coordination could change markets at population scale.
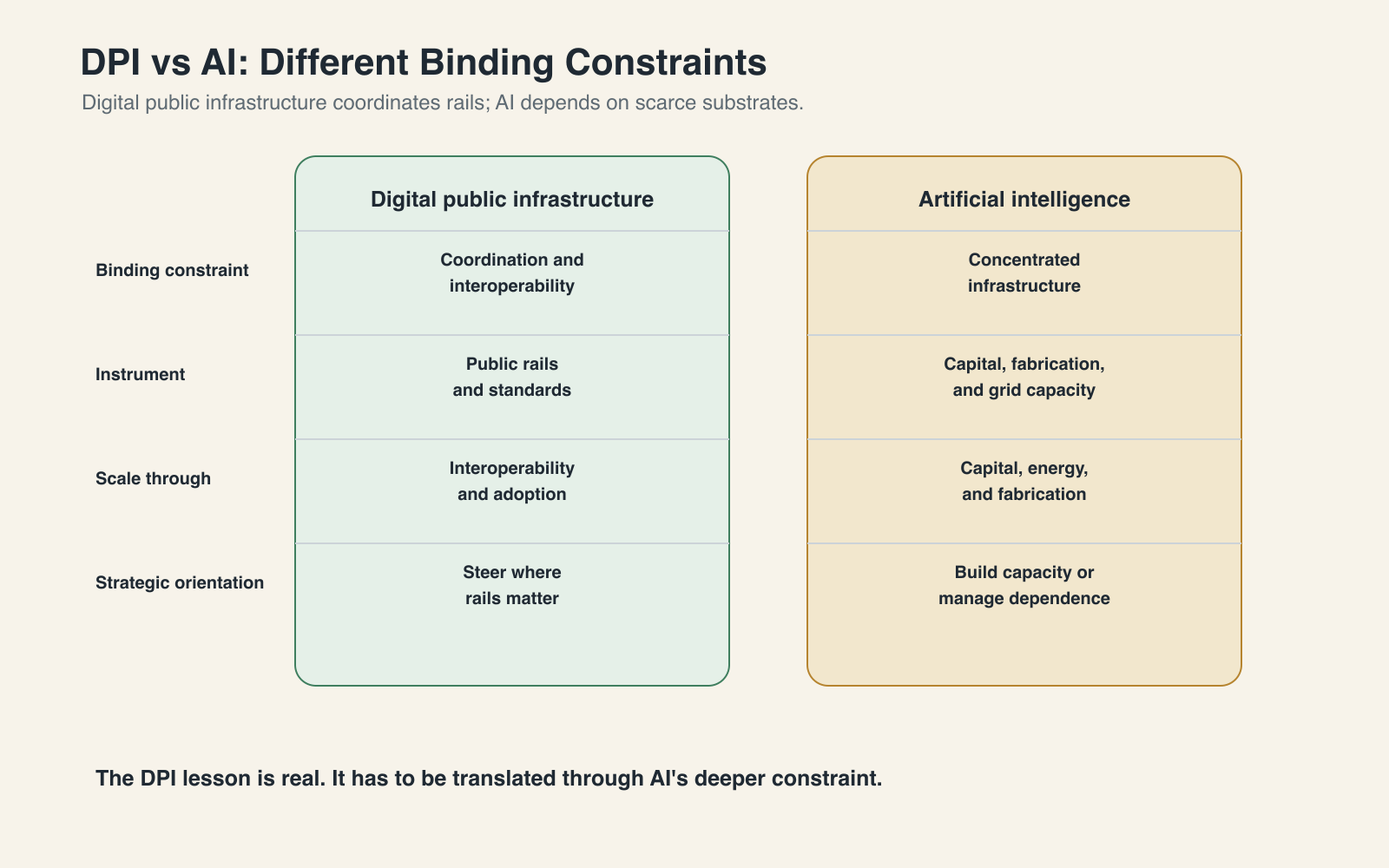
The DPI lesson was real. It can also encourage a mistaken analogy. India’s digital public infrastructure emerged in an environment where the deeper layers needed for large-scale digital coordination, including mobile networks, basic cloud services, and consumer devices, were relatively accessible and not yet the central terrain of great-power technological rivalry. India did not need sovereign semiconductor fabrication, frontier compute clusters, or globally dominant cloud infrastructure to scale digital payments. The core problem was coordination: identity, payments, interoperability, governance, and adoption.
AI changes the economics underneath that coordination layer. Its bottlenecks are not only coordinative; they are infrastructural. DPI worked by coordinating accessible digital rails; AI requires negotiating scarce industrial inputs. Inputs such as compute, chips, cloud capacity, and data centers are becoming more concentrated precisely as they become more economically important.
India’s earlier digital successes remain relevant, but they cannot be reused as a template without modification.
The instruments that worked when the binding constraint was coordination are not the same instruments that work when the binding constraint is concentrated infrastructure. The better way to understand India’s position is as a layered capability structure. India can be strong in deployment while dependent in compute. It can be capable in adaptation while reliant on external model architectures. It can shape how AI diffuses through a large society without controlling the deepest frontier systems beneath it.
Layered capability is uncomfortable because visible capability and strategic dependence can grow together. Application-layer adoption moves quickly; industrial depth accumulates slowly. Software teams can form in months, but fabs, power systems, cloud regions, and specialized supply chains take years or decades to build.
This is the middle-power condition in AI: real scientific, technical, administrative, and market capacity, but not full-stack control over the frontier systems that define the technology.
Selective Sovereignty by Layer
Policy made the layered structure visible at the India AI Impact Summit in New Delhi.
At the summit, the Prime Minister described India’s AI approach through the M.A.N.A.V. frame, five principles covering ethics, accountability, sovereignty, accessibility, and legitimacy in how AI is embedded in society. The emphasis was on legitimacy, access, accountability, and sovereignty over how AI enters public life.
At the same summit, India formally joined the Pax Silica coalition, as part of strategic technology and supply-chain cooperation with the United States. The initiative is framed around securing the “silicon stack”: critical minerals, semiconductor fabrication, advanced AI systems, and deployment infrastructure.
The policy contrast matters. In one domain, India is asserting national governance over legitimacy, inclusion, evaluation, and public purpose. In another, it is coordinating internationally on the semiconductor and hardware supply chains that make frontier AI possible. That is selective sovereignty by layer.
Selective sovereignty is not a clean synthesis. It is a managed compromise: autonomy in some domains, dependence in others, and constant judgment about which dependencies are tolerable. It becomes a strategy only if the country can say why a layer is being ceded, what leverage is being preserved in exchange, and what domestic capability is being built around the dependency. Without that test, the same posture can become passive integration with better language.
The test has to be layer-specific because the constraint is layer-specific. A country may rationally depend on external fabrication capacity where the constraint is industrial and geopolitical, while still needing to build domestic capacity around data centers, energy, evaluation, and deployment. Some dependencies cannot be procured around; some capacities require public authority and coordination.
MANAV’s sovereignty language is therefore best read as sovereignty over data and over the governance, legitimacy, accessibility, and social embedding of AI, not sovereignty over the whole substrate. A country may build domestic depth where durable capability can accumulate, shape outcomes where institutional leverage exists, and integrate strategically where full control is economically unrealistic. The mistake is to confuse access at one level with sovereignty across the whole stack.
Technological Power Decomposes by Layer
Technological power decomposes by layer. The analytical lesson is not that India is behind, or ahead, or somewhere in between.
A country can be strong at one level and dependent at another. A firm can localize the application interface and still depend on foreign retraining pipelines. A government can subsidize compute access without ever controlling the compute it subsidizes. Monolithic talk of “AI capability” or “AI sovereignty” obscures this. There is no single AI to be sovereign over. There is a stack: applications, model adaptation, cloud infrastructure, chips, fabrication, data centers, and energy. Each part has its own concentration logic, its own scale economics, and its own institutional requirements for entry.
The strategic question is not whether a country is in the AI race. The question is where it sits in the stack, on what terms, with what leverage. Subsidizing access to one level does not change the country’s position at the next level down. Localizing the interface does not eliminate dependency beneath it.
Layered analysis also clarifies what is continuous in AI’s emergence, and what is new.
AI did not invent layered technological structure. Electrification, the integrated circuit, telecom networks, and the internet all had deep infrastructures that were capital-intensive, geographically uneven, and shaped by strategic competition. What is new in AI is the compression of timescales, the depth of opacity in some parts of the system, and the speed at which strategically important bottlenecks have become concentrated.
Once the stack is visible, the harder questions begin. Where in the stack does a country accumulate durable capability? Which institutional pathways allow shaping outcomes without controlling everything? What kind of operational capacity does responsible use require when access is cheap but evaluation is scarce?
The internet era treated software as detached from matter. AI returns matter to the picture.