
Operational Capacity Is AI Capability
The scarce layer is not access to models, but the institutional ability to use them well.

The System That Could Not Listen
Between 2005 and 2019, the Dutch Tax and Customs Administration wrongfully accused approximately 26,000 families of fraudulently claiming childcare benefits. Many were forced to repay benefits in full. Families fell into debt. Some lost homes, jobs, and custody of children. In 2021, the scandal helped bring down the Dutch government.
The case is often remembered as a failure of automated decision-making. That is true, but incomplete.
The Dutch system used risk profiles to flag childcare-benefit claims for possible fraud. According to the OECD, families were flagged because of flawed data, minor administrative errors such as missing signatures, and indicators that disproportionately affected households with dual nationality or migrant backgrounds. Amnesty International described the risk-classification system as discriminatory and warned that nationality was used as a risk factor in fraud detection.
The deeper failure was operational. The risk system produced suspicion, but the tax administration lacked enough capacity to evaluate, contest, and correct how that suspicion moved through the agency.
The risk score did not remain an isolated technical output. It entered an administrative machine. Officials treated suspicion as operational fact.
Families struggled to understand why they had been flagged. Appeals and corrections were slow, opaque, or ineffective. The tax administration had a system for generating risk, but not enough capacity for interpreting risk, challenging risk, or reversing harm once risk had hardened into action.
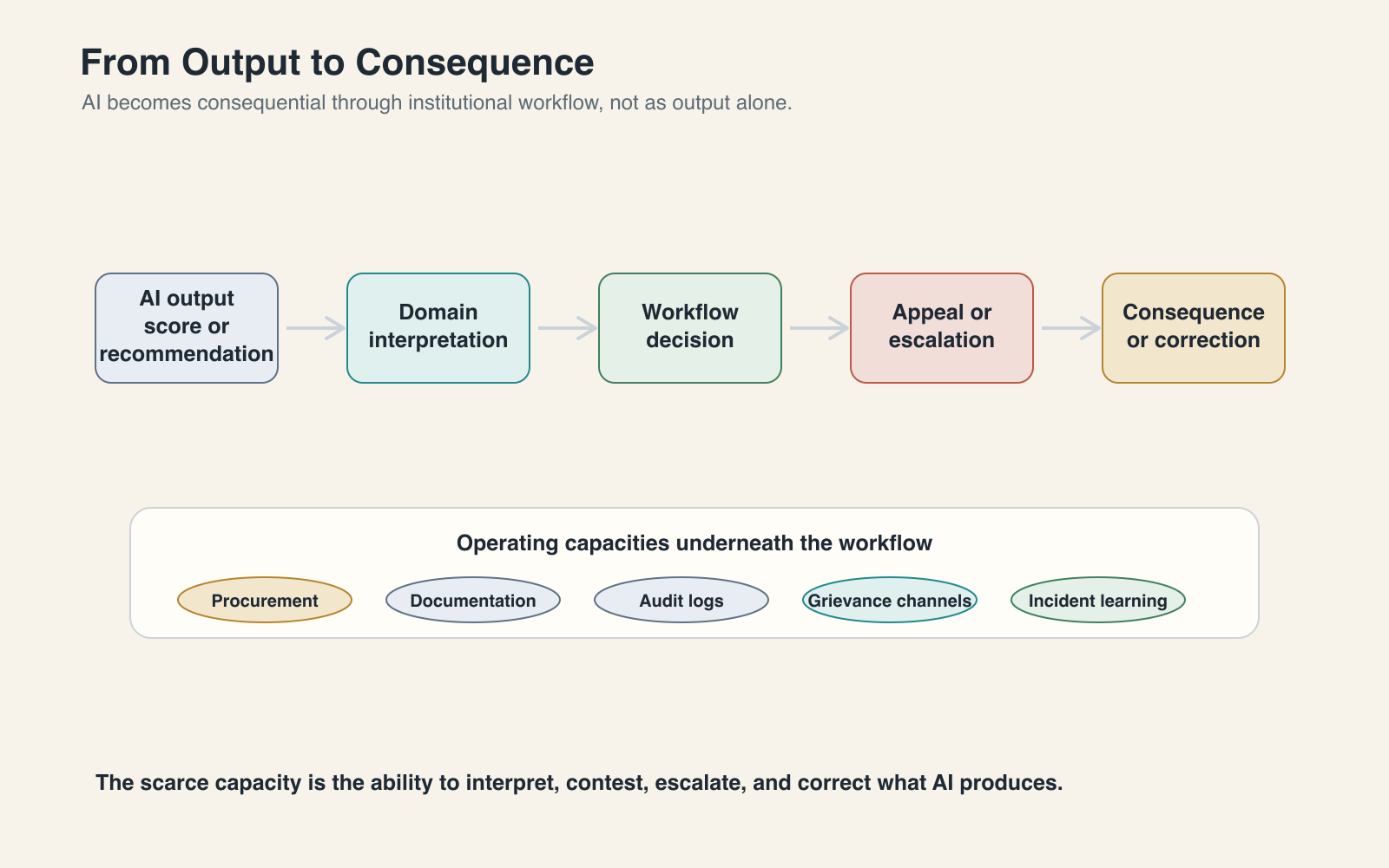
The failure became operational when a technical signal entered an administrative workflow and began shaping consequences. AI governance usually becomes real at this point: not when a model produces an output, but when an institution decides what the output means.
Where AI Actually Touches Society
Most AI debate begins with the model. The model is evaluated, benchmarked, released, criticized, celebrated, or feared. This is understandable: models are visible, named, measured, and easy to discuss as technical progress.
AI rarely touches society as a model alone. It touches society through hospitals, courts, schools, banks, welfare agencies, police departments, tax systems, call centers, farms, insurance firms, and public-service portals. These are not neutral delivery channels. They are institutions with routines, incentives, budgets, procurement rules, expertise, error cultures, and accountability structures.
The previous essay looked beneath the interface and showed how AI access can depend on deeper infrastructure. This essay looks beneath the output and asks a different question: which institutions can interpret, challenge, and govern what the compute produces?
In a hospital, clinicians need to know when to trust an AI system, when to override it, when to escalate uncertainty, and how to document responsibility. A transcription assistant that saves time is different from a diagnostic recommender that changes care pathways. The model matters, but so does the workflow into which it is inserted.
A court can use an AI translation system legitimately only if affected people can challenge errors, officials can identify failure modes, and the court can decide when the translation is reliable enough to shape legal understanding. A mistranslation in a tourist app is an inconvenience. A mistranslation in a legal proceeding can alter someone’s rights.
In agriculture or welfare delivery, the model is only one part of the surrounding system. Data quality, field-level feedback, domain expertise, grievance channels, and operational discipline determine whether the tool can be used well. A crop advisory system that cannot hear back from farmers when advice fails is not a learning system. It is a broadcast system with statistical confidence.
India offers a parallel example of the same pattern. In Telangana, an algorithmic system called Samagra Vedika consolidated data from several government databases to create digital profiles of residents and help officials determine welfare eligibility. A 2024 investigation by Al Jazeera and the Pulitzer Center’s AI Accountability Network reported that the system wrongly denied access to subsidized food for many poor households. In one case, a widow was denied food security benefits after the system confused her late husband with a car owner. The administrative process accepted the database match as operational truth.
The failure was a classic database problem of entity resolution: the technical challenge of determining when different records refer to the same real-world person or household. But once that match entered the administrative workflow, it was no longer experienced as a database error. It became an eligibility decision.
Telangana is not the same case as the Dutch childcare benefits scandal, but both reveal the same institutional pattern. Automated classification entered a public decision process. The system produced an eligibility signal. The public agency lacked adequate mechanisms for explanation, verification, correction, and redress. The affected citizen became responsible for disproving a machine-readable error.
The output may be cheap to generate. The scarce capacity is the surrounding ability to interpret, contest, escalate, and correct it.
The Reallocation of Scarcity
AI lowers the cost of producing certain kinds of outputs. Summaries, translations, recommendations, classifications, images, first drafts, code suggestions, risk scores, and customer responses become easier to generate. The marginal cost falls. The visible abundance expands. Scarcity does not disappear; it moves.
When prediction becomes cheaper, more decisions become candidates for probabilistic inference. When generation becomes cheaper, more text, code, images, classifications, and recommendations can be produced. In both cases, human judgment does not disappear. It shifts toward defining objectives, interpreting outputs, managing exceptions, and deciding when an output is good enough to act on. AI can make inference cheaper; it does not make judgment automatic.
Attention becomes scarce because more outputs compete for institutional judgment. Verification becomes scarce because plausible outputs are not the same as reliable outputs. AI inserts probabilistic systems into organizations built around formal responsibility, making coordination harder. Accountability becomes scarce because the more actors involved in an AI deployment, the easier it becomes for responsibility to diffuse.
In practice, AI-generated outputs can accumulate faster than managers, officials, clinicians, teachers, or caseworkers can verify or integrate them. Without workflow redesign, faster prediction does not translate into faster realized output. It translates into a larger queue of outputs waiting for human interpretation. The bottleneck moves from producing outputs to absorbing them responsibly.
The movement of scarcity explains why a hospital can buy a system before it can evaluate it, a court can pilot a translation tool before it knows how to handle contested outputs, or a welfare agency can automate classification before it has built a meaningful appeals process.
The stakes go beyond workflow efficiency. Institutions do not only process information. They produce legitimate judgment. A court does not merely translate speech; it certifies what can be heard in a legal process. A welfare agency does not merely classify eligibility; it determines whether a public entitlement is recognized. A hospital does not merely summarize symptoms; it authorizes clinical attention. When verification fails, the institution’s claim to judgment weakens.
The reallocation of scarcity is the operational version of the stack problem. In the previous essay, the deeper scarcity sat in chips, compute, cloud infrastructure, and energy. Here, the scarcity sits inside organizations — in their capacity to evaluate, contest, and remain accountable for what AI produces.
For many institutions, the binding constraint will not be whether AI can generate an answer. It will be whether the institution knows what to do with the answer.
Procurement Is Not Capacity
Institutional dependence becomes sharper when AI systems are bought from outside firms.
The firm that builds, trains, hosts, updates, or maintains the system usually understands the technical architecture better than the institution buying it. The institution understands the public setting better than the supplier, but often lacks meaningful access to the model’s design, data, limitations, or update behavior. Each side sees only part of the problem.
Information asymmetry makes procurement look more capable than it is. A hospital, court, school, or welfare agency can buy an AI system, receive documentation, negotiate a contract, and still lack the ability to evaluate how the system behaves in its own workflow. The technical system may be acquired before the institutional capacity to govern it exists.
Probabilistic systems make procurement harder than rule-based software systems. A static software tool can be specified, tested, and audited against relatively stable behavior. A probabilistic model behaves differently across inputs, populations, contexts, and updates, so a system that performs well in a benchmark may fail in a workflow, and a system that is safe in one organization may be risky in another.
Government procurement already struggles with systems whose internal logic agencies cannot fully inspect. Suppliers provide assurances that may not cover real-world use. Agencies rely on performance claims, demos, certifications, or contractual language. When failure occurs, technical responsibility, administrative responsibility, and public accountability can pull apart. The user or citizen sits downstream of that fragmentation.
Procurement documents and compliance rules can name obligations without creating the capacity to meet them. Compliance asks whether a rule has been followed. Operational capacity asks whether an institution can understand, test, govern, and revise the system it is using.
A checklist can be completed while the failure mode remains poorly understood. Fairness, liability, and auditability matter only when institutions have the evidence, access, and expertise to make them operational.
Human-in-the-loop oversight has the same problem. High-stakes AI systems should not be allowed to convert outputs into consequences without accountable human judgment. But a reviewer without time, authority, domain knowledge, technical documentation, or a meaningful appeals process is not oversight in the substantive sense. Operational capacity is what makes human oversight more than a label.
Operational Capacity Is Capability
Operational capacity is the institutional ability to evaluate, govern, audit, procure, and operationalize AI systems in real settings. It is the practical capacity to make AI usable without surrendering judgment to the system being used.
The definition has to stay disciplined. Operational capacity is not regulation in general, technical expertise by itself, organizational readiness in the abstract, or institutional quality as a whole. It is the specific ability to evaluate, contest, revise, and remain accountable for AI-mediated decisions.
Operational capacity is therefore a form of technological capability. Technological capability is usually imagined as the ability to build models, design chips, own compute, or produce frontier research. As AI diffuses, a large share of the social value and social risk will appear in institutions that do not build frontier systems. Hospitals, courts, universities, firms, banks, and welfare agencies will be users, integrators, and accountable decision-makers.
Institutional capability will not be measured by whether these users can train a frontier model. It will be measured by whether they can ask the right questions before deployment, detect failure after deployment, and preserve accountability when outputs shape decisions.
For middle powers, operational capacity is a plausible layer of technological capability. Few countries can quickly build full-stack control over advanced semiconductors, frontier compute, model ecosystems, and hyperscale cloud infrastructure. But many can build stronger institutional capacity around evaluation, procurement, auditing, domain adaptation, and responsible deployment. This capacity is slower than announcement-led AI strategy and less visible than model launches. It accumulates through practice.
An agency that learns how to procure AI responsibly becomes harder to mislead. A hospital that builds evaluation routines becomes less dependent on supplier claims. A court that defines contestability standards before deploying translation or summarization tools protects institutional legitimacy. A public system that tracks failures and allows correction becomes more capable over time.
Operational capacity has a concrete institutional form. It looks like procurement rules that require model documentation before purchase, not after deployment. It includes audit logs that record when an AI output shaped a decision, appeal pathways that allow affected people to contest a machine-readable classification, incident registers that let institutions see whether errors are isolated or patterned, and public-sector technical teams that can test supplier claims instead of merely receiving them.
AI systems update at software speed; procurement rules, appeals processes, audit cultures, legal review, staff training, and institutional memory move at procedural speed. Failure often accumulates in that gap: systems change faster than institutions learn how to govern them.
India’s AI policy language is beginning to move in this direction. The IndiaAI Mission includes a Safe and Trusted AI pillar, and official summit materials describe the need for safety testing, transparency, auditing tools, and interoperable assurance mechanisms. In 2024, the Mission selected eight Responsible AI projects under that pillar, including work on indigenous tools, frameworks, and guidelines for ethical, transparent, and trustworthy AI technologies. Direction becomes capacity only as it produces routines, evidence standards, and institutional memory. Testing and assurance have to become operating capacities, not slogans.
Operational capacity is not a substitute for physical infrastructure; it is the institutional infrastructure that makes judgment, verification, and contestability possible.
The strategic mistake is to treat AI adoption as evidence that an institution is becoming more capable. Adoption can happen quickly. Capability forms slowly. The difference between the two is often invisible until failure occurs.
The Dutch childcare benefits scandal and Telangana’s Samagra Vedika show the same warning in different settings. The danger is not only that automated systems make mistakes. The danger is that institutions adopt systems faster than they build the capacity to govern the mistakes.
The Responsibility Chain Gets Longer
AI will make many institutional outputs easier to produce. Reports, forms, translations, risk scores, eligibility recommendations, summaries, and service responses will become cheaper. That will be useful. In resource-constrained settings, it may be very useful.
Institutions need to know who checks outputs, who contests them, who explains them, who records the decision, who notices clustered errors, and who can stop a system when it begins producing harm. The hardest question is who remains responsible when technical design, procurement, frontline use, and administrative authority each hold part of the causal chain.
Responsibility is now distributed across a longer chain: model provider, system integrator, software supplier, public agency, frontline official, and affected citizen. The more distributed the chain becomes, the more operational capacity has to be designed rather than assumed.
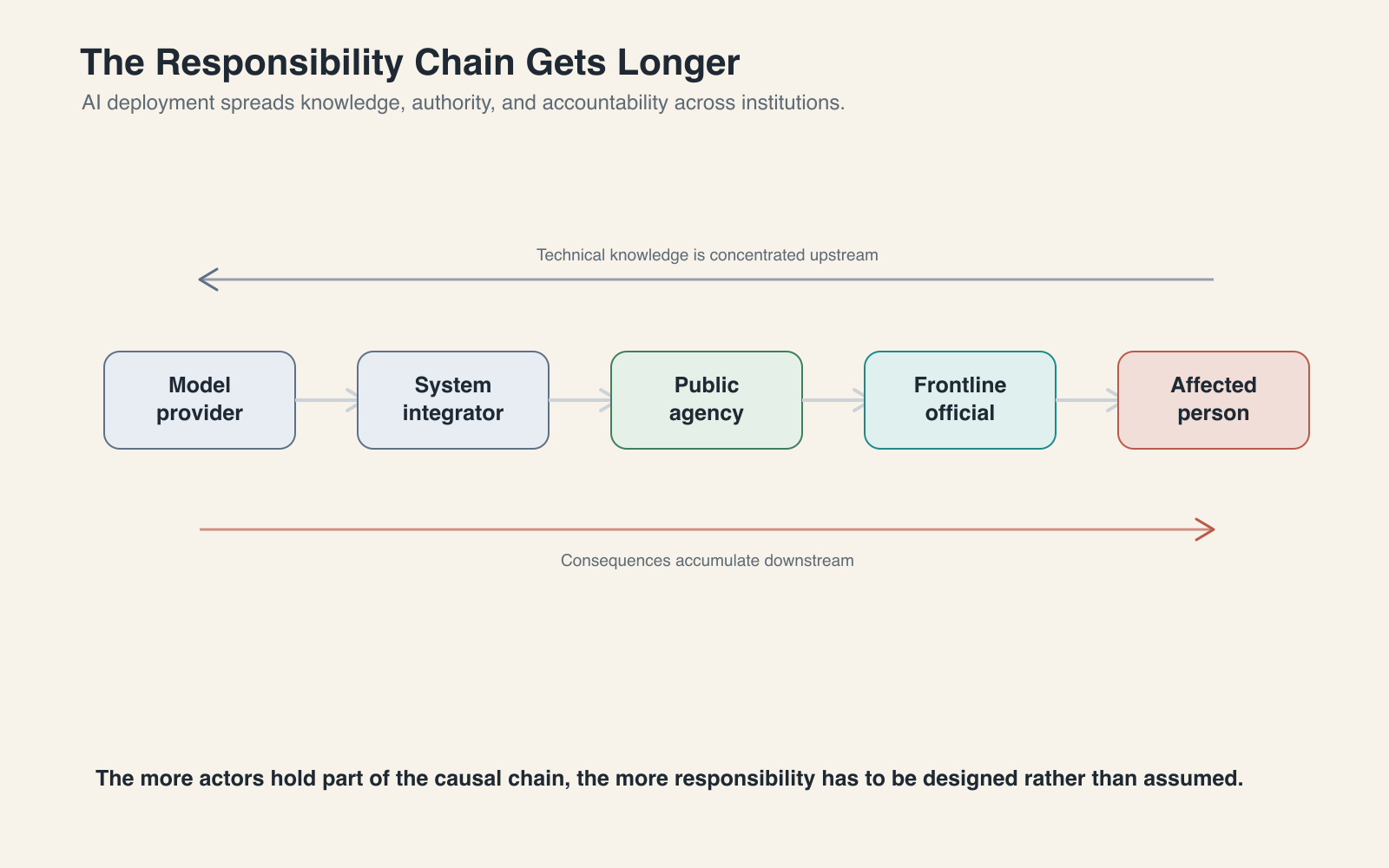
Responsibility is therefore a capability question. A country that cannot build every layer of the AI stack may still build serious capacity at the operational layer. It can develop procurement standards, institutional audit routines, public-sector technical teams, domain-specific evaluation benchmarks, grievance mechanisms, incident registers, and stress tests for high-stakes deployments. It can decide that in some domains, the right form of sovereignty is not owning the model, but refusing to use systems it cannot evaluate.
The next phase of AI will not be defined only by who has the largest models or the most compute. It will also be defined by which institutions can use AI without losing the ability to judge, contest, and correct what AI produces.
When generation becomes cheap, judgment becomes infrastructure.